Kiedy pracujemy w pocie czoła, a Matlab czy Octave jak zwykle sprawnie wykonuje swoje (nasze) obliczenia, posługując się wyłącznie tablicami, zdarza się nam czasami rzucić okiem na ten czy inny arkusz kalkulacyjny, i gdzieś z tyłu głowy pojawia się uczucie lekkiej zazdrości, że tam od razu wszystko widać, co w której kolumnie, co w którym wierszu, że może i taki arkusz liczy gorzej, a przy nieco większych zbiorach danych potrafi stracić przytomność, ale za to – jak wygląda!!!. W kolejnym już wpisie staram się pokazać, że Octave oprócz tego, że liczy, potrafi się również trochę ogarnąć, i potrafi – może i nieśmiało – zacząć wyglądać.
Pierwsze, co przychodzi nam na myśl, kiedy podczas pracy w Octave’ie spoglądamy na arkusz kalkulacyjny, to – oczywiście – ramki danych. Prezentują się wyśmienicie, ale nie każde obliczenia mogą być bezpośrednio z nimi zrealizowane. Komórki, przy ich niezwykłej przydatności, prezentują się raczej średnio. Poznajmy zatem jeszcze jeden rodzaj danych Octave’a – struktury. Elastycznością dorównują komórkom, wyglądem – moim zdaniem – nieco je przewyższają. Są często wykorzystywane do przechowywania wyników obliczeń. Przykładem mogą być sieci neuronowe w Matlabie, gdzie przebiegi treningu i obliczeń przechowywane są właśnie w strukturach. Informacje dotyczące struktur przedstawię w dwóch wpisach. Dzisiaj to co daje nam Octave jako taki (czyli to, co zostało wbudowane w Octave’a), a któryś kolejny wpis poświęcę pewnym dodatkowym możliwościom, jakie niesie ze sobą pakiet struct.
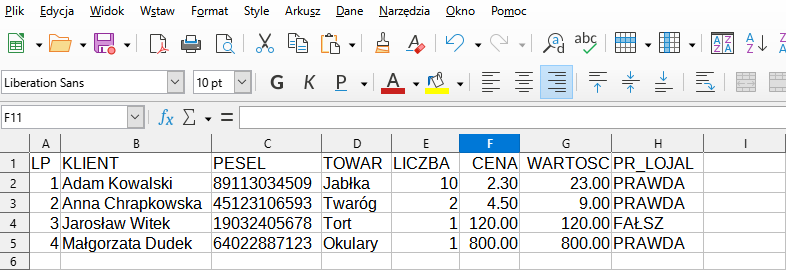
Odtwórzmy zatem przy pomocy struktur choćby pierwsze dwa wiersze (pierwszy wiersz to oczywiście nagłówki danych, drugi – to pierwszy wiersz danych) z prezentowanego fragmentu arkusza kalkulacyjnego.
Na razie z ręki:
>> S = struct('LP',1,'KLIENT','Adam Kowalski','PESEL','89113034509','TOWAR','Jabłka', ...
'LICZBA',10,'CENA',2.30,'WARTOSC',23.00,'PR_LOJAL','PRAWDA')
S =
scalar structure containing the fields:
LP = 1
KLIENT = Adam Kowalski
PESEL = 89113034509
TOWAR = Jabłka
LICZBA = 10
CENA = 2.3000
WARTOSC = 23
PR_LOJAL = PRAWDA
>> size(S)
ans =
1 1
Proszę zwrócić uwagę na charakterystyczny dla Octave’a zapis par argumentów funkcji struct: ’nazwa_argumentu’, wartość_argumentu. I po przecinku kolejna para. Nazwa_argumentu musi być tekstem (obejmujące apostrofy), wartość_argumentu – tylko jeśli też jest tekstem. Tutaj argumentami są nazwy pól, które będą tworzyły strukturę każdego rekordu zmiennej S. Wartości argumentów to zawartości odpowiednich komórek arkusza kalkulacyjnego. Zwróćmy też uwagę na rozmiar struktury (zmienna S): 1 x 1. To oznacza jeden rekord danych. Dodajmy teraz drugi wiersz. Koniecznie musimy poinformować Octave’a, że nową zawartość musi dopisać do zmiennej S (czyli wpisać ją w drugim rekordzie struktury). Gdybyśmy tego nie zrobili, po prostu nadpisalibyśmy dotychczasową zawartość struktury:
>> S(2)= struct('LP',2,'KLIENT','Anna Chrapkowska','PESEL','45123106593','TOWAR','Twaróg', ...
'LICZBA',2,'CENA',2.30,'WARTOSC',23.00,'PR_LOJAL','PRAWDA')
S =
1x2 struct array containing the fields:
LP
KLIENT
PESEL
TOWAR
LICZBA
CENA
WARTOSC
PR_LOJAL
>> size(S)
ans =
1 2
Ponieważ zmienna S zawiera teraz więcej niż jeden rekord (spójrz na wynik polecenia size(S)), pokazywana jest tylko struktura rekordów (nazwy pól). Aby zobaczyć zawartość wybranych rekordów należy wskazać Octave’owi, o który rekord nam chodzi:
>> S(2)
ans =
scalar structure containing the fields:
LP = 2
KLIENT = Anna Chrapkowska
PESEL = 45123106593
TOWAR = Twaróg
LICZBA = 2
CENA = 2.3000
WARTOSC = 23
PR_LOJAL = PRAWDA
I tak kolejno, wiersz po wierszu, moglibyśmy odtwarzać dane z prezentowanego fragmentu arkusza. Czy można to jakoś zautomatyzować? Można. Dane z arkusza zostały wyeksportowane do pliku .csv (proszę pamiętać, by ustawić stronę kodową UTF-8), plik został zaimportowany w Octave’ie do zmiennej typu komórka i zawartość tej zmiennej posłużyła do stworzenia struktury, zawierającej komplet danych z prezentowanego arkusza. Popatrzmy:
% Najpierw zawartość pliku .csv
>> type plik5.csv
LP,KLIENT,PESEL,TOWAR,LICZBA,CENA,WARTOSC,PR_LOJAL
1,Adam Kowalski,89113034509,Jabłka,10,2.30,23.00,PRAWDA
2,Anna Chrapkowska,45123106593,Twaróg,2,4.50,9.00,PRAWDA
3,Jarosław Witek,19032405678,Tort,1,120.00,120.00,FAŁSZ
4,Małgorzata Dudek,64022887123,Okulary,1,800.00,800.00,PRAWDA
% Teraz import pliku do tablicy komórek
>> pkg load io
>> C=csv2cell('plik5.csv')
C =
{
[1,1] = LP
[2,1] = 1
[3,1] = 2
[4,1] = 3
[5,1] = 4
[1,2] = KLIENT
[2,2] = Adam Kowalski
[3,2] = Anna Chrapkowska
[4,2] = Jarosław Witek
[5,2] = Małgorzata Dudek
[1,3] = PESEL
[2,3] = 8.9113e+10
[3,3] = 4.5123e+10
[4,3] = 1.9032e+10
[5,3] = 6.4023e+10
[1,4] = TOWAR
[2,4] = Jabłka
[3,4] = Twaróg
[4,4] = Tort
[5,4] = Okulary
[1,5] = LICZBA
[2,5] = 10
[3,5] = 2
[4,5] = 1
[5,5] = 1
[1,6] = CENA
[2,6] = 2.3000
[3,6] = 4.5000
[4,6] = 120
[5,6] = 800
[1,7] = WARTOSC
[2,7] = 23
[3,7] = 9
[4,7] = 120
[5,7] = 800
[1,8] = PR_LOJAL
[2,8] = PRAWDA
[3,8] = PRAWDA
[4,8] = FAŁSZ
[5,8] = PRAWDA
}
% Zauważmy, że plik .csv zawierał nagłówek danych i w związku z tym pierwszy wiersz tablicy komórek zawiera ten nagłówek:
C(1,:) =
{
[1,1] = LP
[1,2] = KLIENT
[1,3] = PESEL
[1,4] = TOWAR
[1,5] = LICZBA
[1,6] = CENA
[1,7] = WARTOSC
[1,8] = PR_LOJAL
}
% Następnym krokiem jest import zmiennej C - tablicy komórek i zamiana jej zawartości w strukturę. Funkcja
% cell2struct, realizująca ten proces, wymaga w tej sytuacji podania trzech argumentów:
% - pierwszy - C(2:end,:) to zakres zmiennej C, zawierający dane (cała zmienna bez pierwszego wiersza, zawierającego
% nagłówki danych);
% - drugi - C(1,:) to pierwszy wiersz zmiennej C, czyli właśnie nagłówki danych. Zostaną one użyte jako nazwy pól
% tworzonej struktury;
% - trzeci - liczba 2 to drugi wymiar tablicy komórek (kolumny), informujący funkcję cell2struct, że ma wykorzystać
% kolumny wiersza nr 1, by znaleźć nazwy dla pól tworzonej struktury.
>> S=cell2struct(C(2:end,:),C(1,:),2)
S =
4x1 struct array containing the fields:
LP
KLIENT
PESEL
TOWAR
LICZBA
CENA
WARTOSC
PR_LOJAL
Skoro mamy strukturę z kilkoma rekordami danych (liczbę rekordów pokazuje nam wynik polecenia tworzącego strukturę), obejrzyjmy jej zawartość. Pierwszy sposób już wypróbowaliśmy: nazwa zmiennej z numerem rekordu w roli indeksu, np. S(3) – zawartość trzeciego rekordu zmiennej S. I – oczywiście – wynik, który przedstawi nam Octave zawsze możemy przypisać do nowej zmiennej, tworząc nową strukturę, zawierającą wybrany przez nas zestaw rekordów (np. S2 = S(3)).
>> S(3)
ans =
scalar structure containing the fields:
LP = 3
KLIENT = Jarosław Witek
PESEL = 1.9032e+10 % Niepokojąco wygląda ten PESEL, prawda? Naprawimy to za chwilę
TOWAR = Tort
LICZBA = 1
CENA = 120
WARTOSC = 120
PR_LOJAL = FAŁSZ
Możemy też oglądać przekrój zawartości wybranego pola całej struktury, albo tylko jej wybranych rekordów.
>> S.KLIENT ans = Adam Kowalski ans = Anna Chrapkowska ans = Jarosław Witek ans = Małgorzata Dudek >> S(1).KLIENT ans = Adam Kowalski >> S(1:2).KLIENT ans = Adam Kowalski ans = Anna Chrapkowska >> S([1 3]).KLIENT ans = Adam Kowalski ans = Jarosław Witek
I na koniec jeszcze: co z tym PESELEM? Ponieważ składa się z samych cyfr, został zinterpretowany podczas importu z pliku .csv jako liczba i teraz wyświetlany jest w postaci wykładniczej. Zamienimy go na tekst, aby był wyświetlany popranie. Aby nie komplikować opowieści o strukturach nie użyjemy do tej zamiany żadnej pętli – po prostu naprawimy każdy rekord danych oddzielnie. Do zamiany liczby na tekst użyjemy funkcji o nazwie num2str, która zamieni liczbę na tekst, wyglądający dokładnie tak jak liczba.
% Stan wejściowy: PESEL jest liczbą wyświetlaną w postaci wykładniczej >> S.PESEL ans = 8.9113e+10 ans = 4.5123e+10 ans = 1.9032e+10 ans = 6.4023e+10 % Zmiana liczby na tekst w polu PESEL każdego rekordu (średnik na końcu polecenia zapobiega wyświetleniu wyniku % polecenia w oknie poleceń) >> S(1).PESEL=num2str(S(1).PESEL); >> S(2).PESEL=num2str(S(2).PESEL); >> S(3).PESEL=num2str(S(3).PESEL); >> S(4).PESEL=num2str(S(4).PESEL); % Rezultat >> S.PESEL ans = 89113034509 ans = 45123106593 ans = 19032405678 ans = 64022887123
Tyle na dzisiaj. Pozostałe informacje o strukturach w którymś kolejnym wpisie. :))