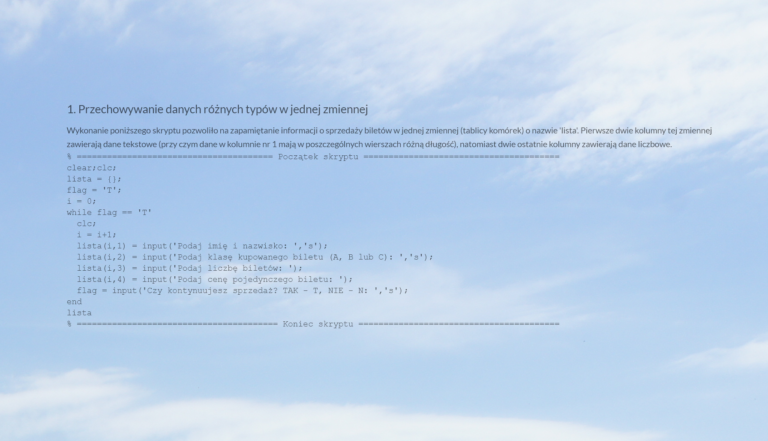
Szanowni Państwo
Ramkę danych (dataframe) można wyobrazić sobie jako tabelę ze zmiennymi w kolumnach. Ramka danych może przechowywać w poszczególnych kolumnach zmienne liczbowe i tekstowe jednocześnie. Kolumny posiadają nazwy i można się do nich odwoływać zarówno poprzez indeks (jak w tablicach), jak i poprzez nazwę. Wiersze ramki danych tworzą rekordy danych (każdy wiersz to oddzielny, kompletny zestaw danych). Tak w przypadku ramek danych, jak i w przypadku innych, zaawansowanych typów danych w aplikacji Octave obowiązuje ta sama zasada: do wykonywania obliczeń najlepiej nadają się tablice (macierze, wektory – cokolwiek chcecie); ramki danych najlepiej sprawdzają się podczas prezentacji danych oraz importu danych zewnętrznych, np. z plików tekstowych (chociaż tu ustępują pierwszeństwa komórkom – ale o komórkach opowiemy sobie innym razem).
Ramki danych pozwolą nam przećwiczyć pracę z pakietami Octave’a – nie ma ich bowiem w samym pakiecie. Wymagają załadowania do pamięci pakietu o nazwie dataframe. Ale to przećwiczymy już za chwilę w praktyce.
Jako pierwsze – załadowanie do pamięci Octave’a pakietu dataframe – jak pamiętamy z poprzedniego wpisu, jest on niezbędny do pracy z ramkami danych
>> pkg load dataframe >>
Octave jest bardzo umiarkowany w pochwałach, ale nie szczędzi informacji o kłopotach. Skoro nic nie mówi – udało się. Pakiet dataframe został załadowany do pamięci.
Wyświetlenie zawartości pliku z danymi
>> type plikLista.txt Jan Kowalski,A,1,100 Anna Japok,B,3,85 Janusz Nowak,C,4,60 Iwona Stobrawa,A,5,100
Naszą ramkę danych zbudujemy z danych przechowywanych w pliku o nazwie plikLista.txt. Przed rozpoczęciem odczytu danych z pliku tekstowego warto obejrzeć zawartość pliku w dowolnym programie. Pozwala to na rozpoznanie elementów struktury pliku: nagłówka (bądź jego braku), separatora (czyli znaku oddzielającego poszczególne kolumny w pliku, separatora dziesiętnego i innych podobnych elementów, których prawidłowe ustawienie podczas odczytu danych z pliku może zadecydować o sukcesie lub niepowodzeniu całej operacji. W przypadku pakietów Matlab / Octave można wyświetlić zawartość badanego pliku w oknie edytora lub, jak w naszym przypadku, użyć polecenia type plikLista.txt, co pozwoli na wyświetlenie zawartości pliku w oknie poleceń. Zauważmy, że dane w pliku nie mają nagłówka, poszczególne pola danych (cztery w każdym wierszu) oddzielone są od siebie przecinkami, dane tekstowe nie są też w żaden szczególny sposób wyodrębnione – nie są zamknięte w cudzysłowy ani w apostrofy.
Tworzenie ramki danych z pliku *.csv (*.txt)
>> df = dataframe('plikLista.txt')
df = dataframe with 4 rows and 4 columns
Src: plikLista.txt
_1 X1 X2 X3 X4
Nr char char double double
1 Jan Kowalski A 1 100
2 Anna Japok B 3 85
3 Janusz Nowak C 4 60
4 Iwona Stobrawa A 5 100
Zawartość pliku tekstowego została zaimportowana do zmiennej df, która jest ramką danych zawierającą 4 wiersze i 4 kolumny. Podczas importu zostały im nadane automatycznie nazwy X1, X2, X3 i X4 (w pliku źródłowym nie było nagłówka danych, który mógłby dostarczyć nazw tworzonym kolumnom). Jak łatwo zauważyć, zawartość pliku tekstowego została prawidłowo zaimportowana do zmiennej Octave’a. Zauważyć też można, że z lewej strony zawartości zmiennej df pojawiła się kolumna oznaczona jako _1 i typu Nr. Octave „nie zauważył” jej, zliczając kolumny ramki danych. Ta kolumna zawiera indeksy – numery wierszy ramki danych.
Oglądanie danych ramki df
>> df(1,1) ans = dataframe with 1 rows and 1 columns Src: plik_1.csv _1 X1 Nr char 1 Jan Kowalski >> df(1,:) ans = dataframe with 1 rows and 4 columns Src: plik_1.csv _1 X1 X2 X3 X4 Nr char char double double 1 Jan Kowalski A 1 100 >> df(1:3,:) ans = dataframe with 3 rows and 4 columns Src: plik_1.csv _1 X1 X2 X3 X4 Nr char char double double 1 Jan Kowalski A 1 100 2 Anna Japok B 3 85 3 Janusz Nowak C 4 60 >> df([1 1 1 3],:) ans = dataframe with 4 rows and 4 columns Src: plik_1.csv _1 X1 X2 X3 X4 Nr char char double double 1 Jan Kowalski A 1 100 1 Jan Kowalski A 1 100 1 Jan Kowalski A 1 100 3 Janusz Nowak C 4 60 >> df(:,end) ans = dataframe with 4 rows and 1 columns Src: plik_1.csv _1 X4 Nr double 1 100 2 85 3 60 4 100
Zobaczyliśmy różne fragmenty ramki df. W celu wyselekcjonowania odpowiedniego zakresu danych ze zmiennej df używaliśmy składni typowej dla tablic Octave’a. Zwróćmy uwagę, że wyświetlone tą metodą fragmenty ramki df były również ramkami danych.
Teraz wypróbujmy innego sposobu dostępu do danych przechowywanych w ramce danych df.
>> df.X1 % Ten sposób dostępu do danych zwraca dane w postaci tablic liczbowych lub tekstowych
% czyli podstawowych, wbudowanych typów danych Octave'a
ans =
Jan Kowalski
Anna Japok
Janusz Nowak
Iwona Stobrawa
>> class(df.X1) % Jak widać polecenie df.X1 wyprodukuje zmienną tekstową, a nie zmienną typu dataframe
ans = char
>> df.X1
>> size(df.X1) % rozmiar zwracanych danych: cztery wiersze, każdy po czternaście znaków
ans =
4 14
Edycja nazw kolumn ramki danych
>> df.colnames
ans =
X1
X2
X3
X4
>> df.colnames = {'NABYWCA';'KLASA';'LICZBA';'CENA'}
df = dataframe with 4 rows and 4 columns
Src: plikLista.txt
_1 NABYWCA KLASA LICZBA CENA
Nr char char double double
1 Jan Kowalski A 1 100
2 Anna Japok B 3 85
3 Janusz Nowak C 4 60
4 Iwona Stobrawa A 5 100
Ramka danych ma kilka skojarzonych ze sobą kolekcji, do których odwołujemy się przy pomocy składni zaprezentowanej powyżej: zmienna.kolekcja. Kolekcja colnames przechowuje nazwy wszystkich kolumn ramki danych. Zatem polecenie df.colnames wyświetliło nazwy kolumn ramki danych df. Możemy również przypisywać własną zawartość tej kolekcji, czyli zmieniać nazwy kolumn. Przykład takiej operacji został zaprezentowany powyżej. Należy pamiętać, że nowa zawartość musi być podana jako komórka – musi być ujęta w nawiasy klamrowe '{ }’.
O komórkach i strukturach opowiemy sobie w jednym z kolejnych wpisów.
Dodawanie kolumny do ramki danych
>> df.WARTOSC = df.LICZBA.*df.CENA df = dataframe with 4 rows and 5 columns _1 NABYWCA KLASA LICZBA CENA WARTOSC Nr char char double double double 1 Jan Kowalski A 1 100 100 2 Anna Japok B 3 85 255 3 Janusz Nowak C 4 60 240 4 Iwona Stobrawa A 5 100 500
Należy zwrócić uwagę na łatwość dodawania nowych kolumn do ramki danych. Powyższy przykład pokazuje utworzenie nowej kolumny o nazwie WARTOSC, której poszczególne elementy stanowią iloczyn odpowiednich wartości kolumn LICZBA i CENA. Proszę zwrócić uwagę na zastosowanie operatora mnożenia tablicowego ( .* )